【Spark Summit EU 2016】Sparklint:Spark监控,识别与优化利器
本文共 228 字,大约阅读时间需要 1 分钟。
更多精彩内容参见云栖社区大数据频道;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问。
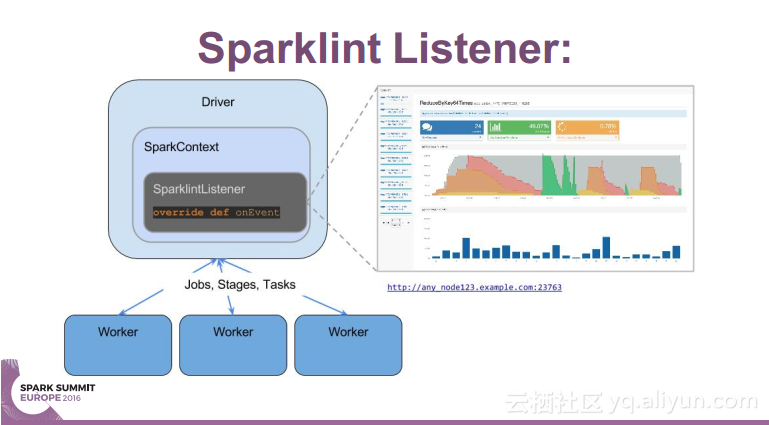
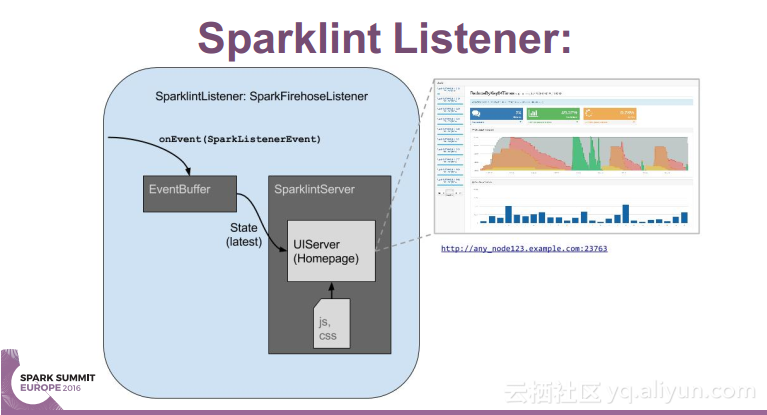
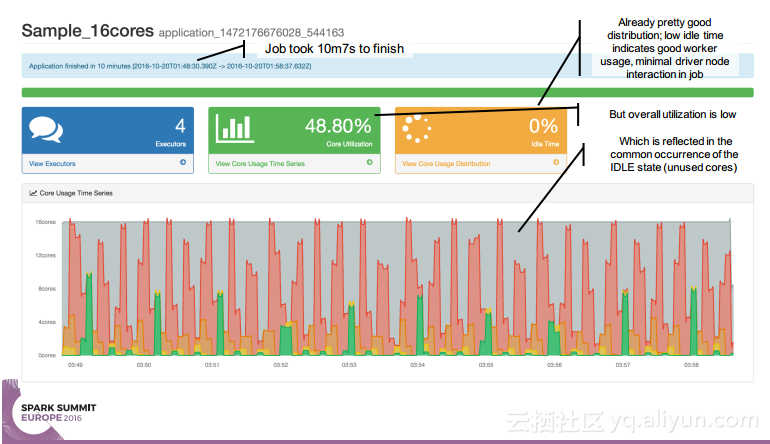
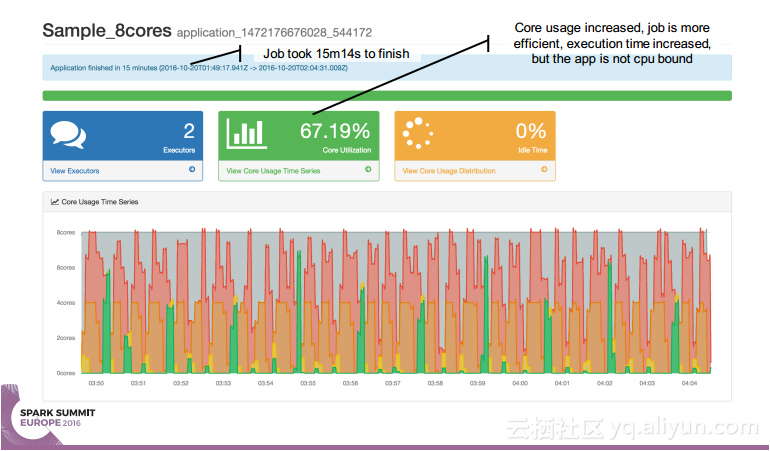
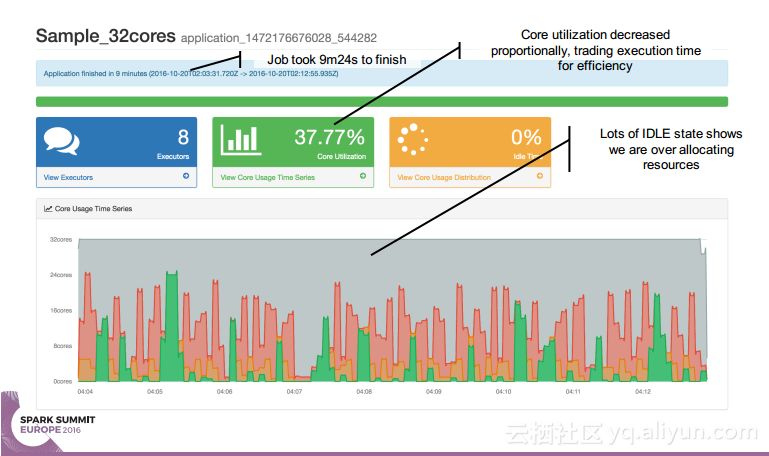
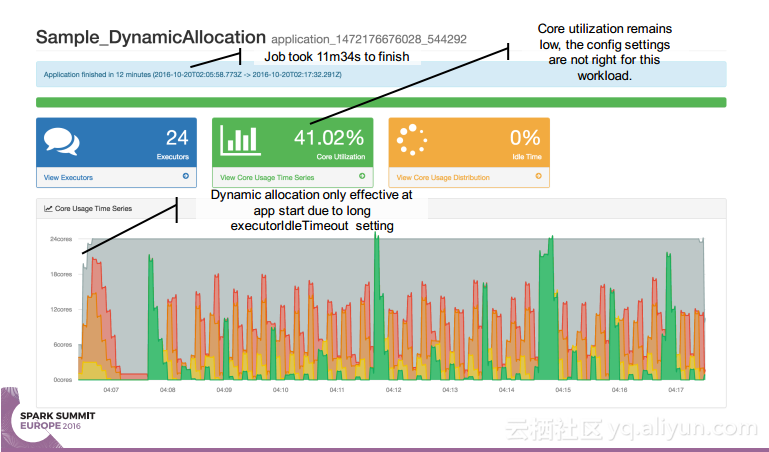
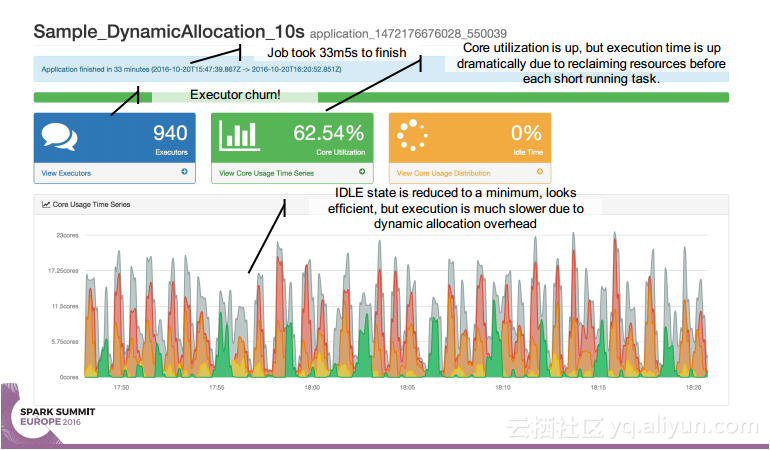
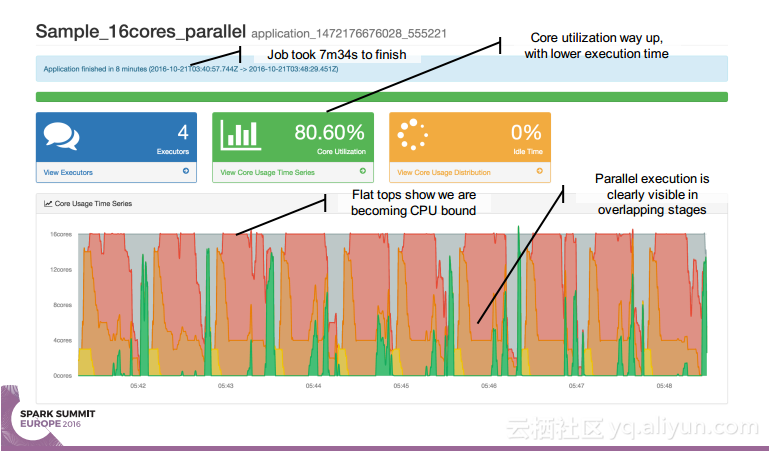
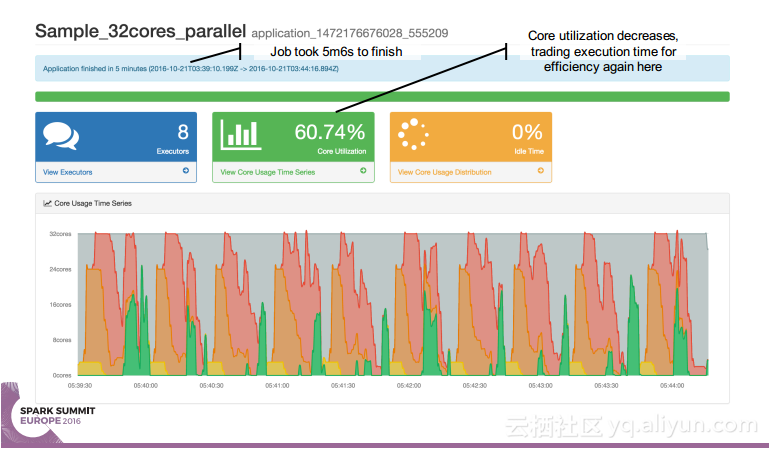
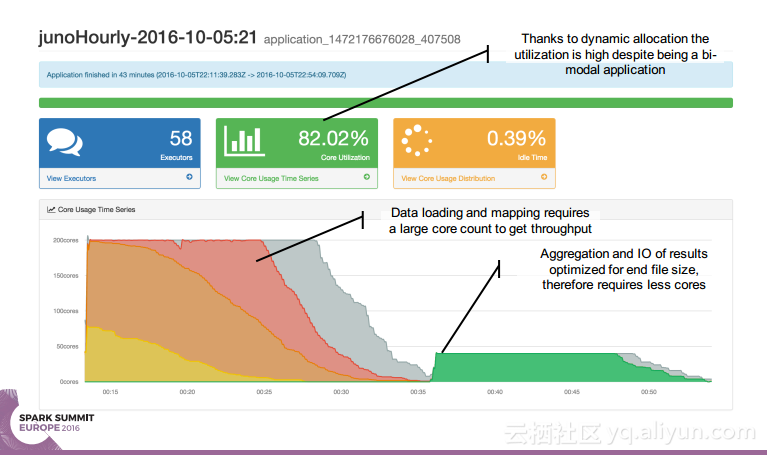
本讲义出自 Simon Whitear在Spark Summit EU 2016上的演讲,主要介绍了用于监控,识别并优化低效Spark的工具Sparklint。由于成功的Spark集群的规模往往会迅速扩张,往往会出现能力与任务不匹配的情况并造成资源竞争,为了使得Spark集群的效率得到提升,所以需要Sparklint这样的监控优化工具。








转载地址:http://pkmja.baihongyu.com/
你可能感兴趣的文章
MD5加密算法(转)
查看>>
Vue.2.0.5-条件渲染
查看>>
[译]AngularJS Services 获取后端数据
查看>>
scapy流量嗅探简单使用
查看>>
Hadoop Hive概念学习系列之hive的正则表达式初步(六)
查看>>
Leetcode: Combination Sum IV && Summary: The Key to Solve DP
查看>>
Hibernate整合C3P0实现连接池
查看>>
Apache vs. Nginx
查看>>
C++数值类型极限值的获取
查看>>
Bag标签之中的一个行代码实行中文分词实例3
查看>>
3295 落单的数 九章算法面试题
查看>>
synchronized同步块和volatile同步变量
查看>>
spark入门
查看>>
计算某个特定分隔符分隔的字符串的和
查看>>
解决IE11 Array没有find的方法
查看>>
webpack 引入jquery和第三方jquery插件
查看>>
损失函数的概率验证及性质
查看>>
C#-----------------------------回收机制中Destroy与null的作用
查看>>
mysql读写分离总结
查看>>
ubuntu默认防火墙
查看>>